
This paper is available on Arxiv under CC 4.0 license.
Authors:
(1) Seth P. Benson, Carnegie Mellon University (e-mail: spbenson@andrew.cmu.edu);
(2) Iain J. Cruickshank, United States Military Academy (e-mail: iain.cruickshank@westpoint.edu)
Table of Links
III. METHODOLOGY
In order to characterize the media bias of cable news transcripts, we devised a four-step procedure. The procedure begins with data cleaning, then transcript analysis, and then concludes with program comparison and clustering. Throughout these steps, the key dimensions of analysis were what is being said on cable news (identified through named entity recognition) and how those topics are portrayed (classified through stance analysis). The following figure, Figure 1, summarizes the proposed method.
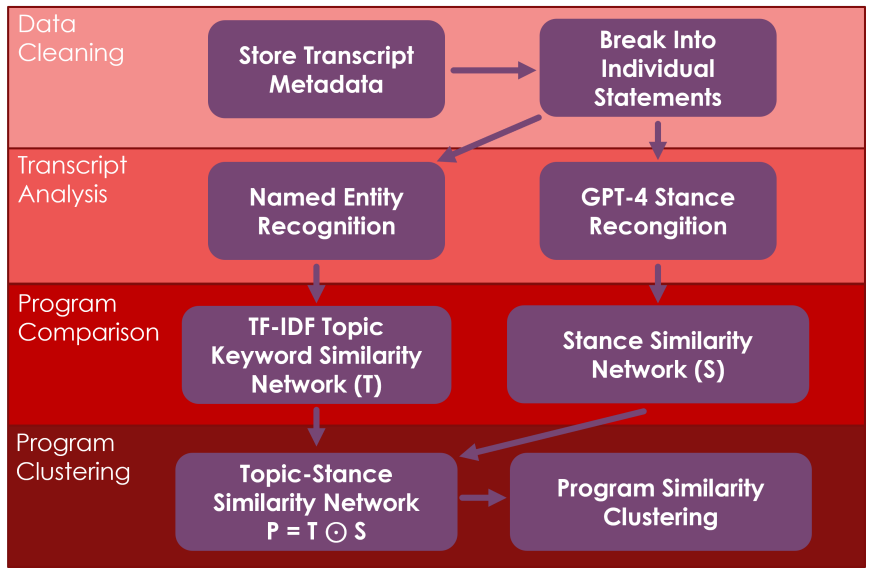
A. TRANSCRIPT CLEANING
Using NexisUni, we obtained all transcripts from Fox News, MSNBC, and CNN from January 2020 to December 2020, a total of 14,000 transcripts. These networks were selected because they are thought of as the major networks in cable television and their transcripts had been used in previous cable news research [37]. Using the information on the first page of each transcript, which was detailed in a consistent way throughout all transcripts, we retrieved metadata including the program name and the date it aired. Afterward, transcripts were parsed to create a collection of statements and associated speakers.
This allowed for a list of all statements made in a transcript to be collectively analyzed. Using the recorded date, the transcripts were divided by month so that the program analysis could be done at a monthly level and results could be compared across months. Since most news cycles occur between a weekly and monthly time frame, we choose to analyze at the monthly level but note the procedure could be done at any time scale. The month level was selected so that each program could have sufficient associated transcripts for analysis.

B. NAMED ENTITY RECOGNITION
The first part of transcript analysis was determining what is being said on cable news through named entity recognition. This is done through the EntityRecognizer method in the spaCy python package [38]. The EntityRecongizer method identifies proper words or phrases within a text such as names, places, or organizations. We sort these by frequency within transcripts, cutting entities that are likely not news topics such as the time, quantities, cardinal directions, and percentages.
All named entities that are in the top five entities in a transcript and are used in at least three sentences are marked as keywords for that transcript. Entities outside of these criteria are typically not main topics in a transcript. Additionally, entity limitations were required to limit the API requests and time required for the stance analysis.
Before deciding on named entity recognition as the means of discerning what is being talked about, we also investigated different approaches for topic identification. One was using topic modeling to split transcripts into multiple topics and take the most used non-common words within each topic as keywords by both LDA [39] and BERTopic [40]. The other approach was a broad approach that selected the most frequently used nouns within each transcript as keywords. Each of these approaches returned similar results but they were less effective at differentiating programs and creating consistent clusters than by using the top entities from the transcripts.
C. STANCE ANALYSIS
After determining the keywords in a cable news program we turned to determining the expressed stance towards those words. We opted to use GPT-4 [41] due to it being state-ofthe-art at the time of this research to accomplish this, but note that other LLMs could also be used for this analysis [33], [36]. For each keyword identified in a transcript, we determine the transcript’s stance towards that keyword to be the average of the individual sentence stances towards the keyword across all of the sentences it is the main subject of.
Sentence level analysis was used because news programs often switch between several topics over the course of any given person’s statement (e.g. a newscaster presenting an opinion monologue), so analyzing at the sentence level gives a better understanding of the sentiment toward any one topic.
We use one prompt to determine both whether a keyword is the main subject of a sentence and what the sentence stance is towards the keyword if it is a main subject.
For each sentence, GPT-4 was asked to "respond NO" if the keyword is not "the main subject in the sentence" and "return whether the statements are POSITIVE, NEUTRAL, or NEGATIVE towards" the subject if it is the main subject. After receiving the GPT-4 output, these results are quantitatively mapped so that POSITIVE equals a stance of one, NEUTRAL equals a stance of zero, and NEGATIVE equals a stance of a negative one. The average of these returned values is stored as the transcript’s overall stance towards a keyword topic.
Prior to using stance, we calculated the sentiment for each sentence in a transcript using the VADER Composite Polarity score [42]. VADER sentiment analysis uses the full context of a text, including punctuation and capitalization, to determine its sentiment [42].
However, because VADER can only return how positive or negative text in general, not specifically towards a subject, it proved to be much less effective at differentiating programs than stance analysis. Evidence is shown in the results section.
D. PROGRAM COMPARISON

E. PROGRAM CLUSTERING

This paper is available on Arxiv under CC 4.0 license.