

Authors:
(1) Pinelopi Papalampidi, Institute for Language, Cognition and Computation, School of Informatics, University of Edinburgh;
(2) Frank Keller, Institute for Language, Cognition and Computation, School of Informatics, University of Edinburgh;
(3) Mirella Lapata, Institute for Language, Cognition and Computation, School of Informatics, University of Edinburgh.
Table of Links
- Abstract and Intro
- Related Work
- Problem Formulation
- Experimental Setup
- Results and Analysis
- Conclusions and References
- A. Model Details
- B. Implementation Details
- C. Results: Ablation Studies
5. Results and Analysis
Usefulness of Knowledge Distillation We first investigate whether we improve TP identification, as it is critical to the trailer generation task. We split the set of movies with ground-truth scene-level TP labels into development and test set and select the top 5 (@5) and top 10 (@10) shots per TP in a movie. As evaluation metric, we consider Partial Agreement (PA; [41]), which measures the percentage of TPs for which a model correctly identifies at least one ground-truth shot from the 5 or 10 shots selected from the movie (see Appendix for details).
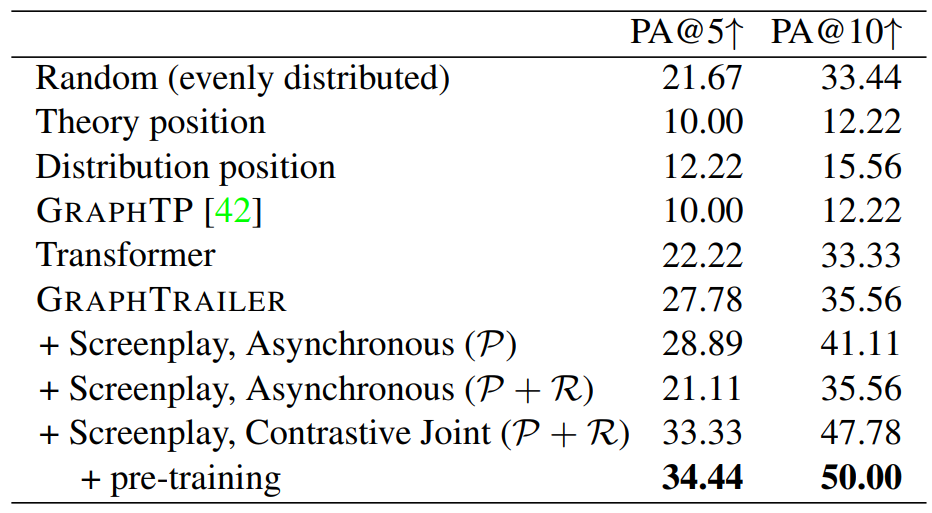
Table 2 summarizes our results on the test set. We consider the following comparison systems: Random selects shots from evenly distributed sections (average of 10 runs); Theory assigns TP to shots according to screenwriting theory (e.g., “Opportunity” occurs at 10% of the movie, “Change of plans” at 25%, etc.); Distribution selects shots based on their expected position in the training data; GRAPHTP is the original model of [42] trained on screenplays (we project scene-level TP predictions to shots); Transformer is a base model without graph-related information. We use our own model, GRAPHTRAILER, in several variants for TP identification: without and with access to screenplays, trained only with the prediction consistency loss (P), both prediction and representation losses (P + R), and our contrastive joint training regime.
We observe that GRAPHTRAILER outperforms all baselines, as well the Transformer model. Although the latter encodes long-range dependencies between shots, GRAPHTRAILER additionally benefits from directly encoding sparse connections learnt in the graph. Moreover, asynchronous knowledge distillation via the prediction consistency loss (P) further improves performance, suggesting that knowledge contained in screenplays is complementary to what can be extracted from video. Notice that when we add the representation consistency loss (P + R), performance deteriorates by a large margin, whereas the proposed training approach (contrastive joint) performs best. Finally, pretraining offers further gains, albeit small, which underlines the benefits of the screenplay-based network.
Trailer Quality We now evaluate the trailer generation algorithm of GRAPHTRAILER on the held-out set of 41 movies (see Table 1). As evaluation metric, we use accuracy, i.e., the percentage of correctly identified trailer shots and we consider a total budget of 10 shots for the trailers in order to achieve the desired length (∼2 minutes).
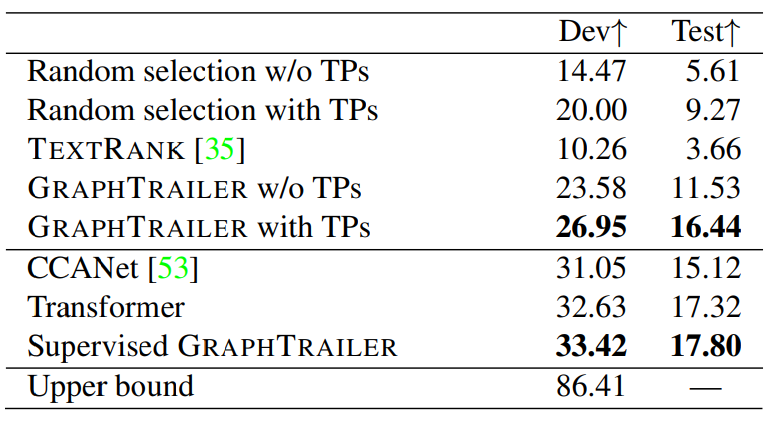
We compare GRAPHTRAILER against several unsupervised approaches (first block in Table 3) including: Random selection among all shots and among TPs identified by GRAPHTRAILER; we also implement two graph-based systems based on a fully-connected graph, where nodes are shots and edges denote the degree of similarity between them. This graph has no knowledge of TPs, it is constructed by calculating the similarity between generic multimodal representations. TEXTRANK [35] operates over this graph to select shots based on their centrality, while GRAPHTRAILER without TPs traverses the graph with TP and sentiment criteria removed (Equation 2). For the unsupervised systems which include stochasticity and produce proposals (Random, GRAPHTRAILER), we consider the best proposal trailer. The second block of Table 3 presents supervised approaches which use noisy trailer labels for training. These include CCANet [53], which only considers visual information and computes the cross-attention between movie and trailer shots, and a vanilla Transformer trained for the binary task of identifying whether a shot should be in the trailer without considering screenplays, sentiment or TPs. Supervised GRAPHTRAILER consists of our video based network trained on the same data as the Transformer.
GRAPHTRAILER performs best among unsupervised methods. Interestingly, TEXTRANK is worse than random, illustrating that tasks like trailer generation cannot be viewed as standard summarization problems. GRAPHTRAILER without TPs still performs better than TEXTRANK and random TP selection.[7] With regard to supervised approaches, we find that using all modalities with a standard architecture (Transformer) leads to better performance than sophisticated models using visual similarity (CCANet). By adding graph-related information (Supervised GRAPHTRAILER), we obtain further improvements.

We perform two ablation studies on the development set for GRAPHTRAILER. The first study aims to assess how the different training regimes of the dual network influence downstream trailer generation performance. We observe in Table 4 that asynchronous training does not offer any discernible improvement over the base model. However, when we jointly train the two networks (video- and screenplay-based) using prediction and representation consistency losses, performance increases by nearly 3%. A further small increase is observed when the screenplay-based network is pre-trained on more data.
The second ablation study concerns the criteria used for performing random walks on the graph G. As shown in Table 5, when we enforce the nodes in the selected path to be close to key events (similarity + TPs) performance improves. When we rely solely on sentiment (similarity + sentiment), performance drops slightly. This suggests that in contrast to previous approaches which mostly focus on superficial visual attractiveness [53, 57] or audiovisual sentiment analysis [47], sentiment information on its own is not sufficient and may promote outliers that do not fit well in a trailer. On the other hand, when sentiment information is combined with knowledge about narrative structure (similarity + TPs + sentiment), we observe the highest accuracy. This further validates our hypothesis that the two theories about creating trailers (i.e., based on narrative structure and emotions) are complementary and can be combined.
Finally, since we have multiple trailers per movie (for the dev set), we can measure the overlap between their shots (Upper bound). The average overlap is 86.14%, demonstrating good agreement between trailer makers and a big gap between human performance and automatic models.
Finally, since we have multiple trailers per movie (for the dev set), we can measure the overlap between their shots (Upper bound). The average overlap is 86.14%, demonstrating good agreement between trailer makers and a big gap between human performance and automatic models.
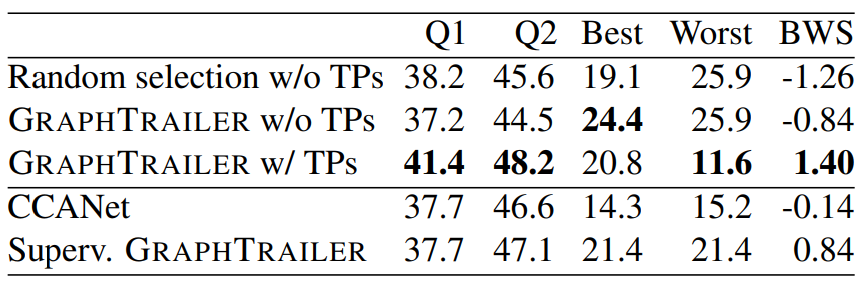
Human Evaluation We also conducted a human evaluation study to assess the quality of the generated trailers. For human evaluation, we include Random selection without TPs as a lower bound, the two best performing unsupervised models (i.e., GRAPHTRAILER with and without TPs), and two supervised models: CCANet, which is the previous state of the art for trailer generation, and the supervised version of our model, which is the best performing model according to automatic metrics.[8] We generated trailers for all movies in the held-out set. We then asked Amazon Mechanical Turk (AMT) crowd workers to watch all trailers for a movie, answer questions relating to the information provided (Q1) and the attractiveness (Q2) of the trailer, and select the best and worst trailer. We collected assessments from five different judges per movie.
Table 6 shows that GRAPHTRAILER with TPs provides on average more informative (Q1) and attractive (Q2) trailers than all other systems. Although GRAPHTRAILER without TPs and Supervised GRAPHTRAILER are more often selected as best, they are also chosen equally often as worst. When we compute standardized scores (z-scores) using best-worst scaling [31], GRAPHTRAILER with TPs achieves the best performance (note that is also rarely selected as worst) followed by Supervised GRAPHTRAILER. Interestingly, GRAPHTRAILER without TPs is most often selected as best (24.40%), which suggests that the overall approach of modeling movies as graphs and performing random walks instead of individually selecting shots helps create coherent trailers. However, the same model is also most often selected as worst, which shows that this naive approach on its own cannot guarantee good-quality trailers.
We include video examples of generated trailers based on our approach in the Supplementary Material. Moreover, we provide a step-by-step graphical example of our graph traversal algorithm in the Appendix.
Spoiler Alert! Our model does not explicitly avoid spoilers in the generated trailers. We experimented with a spoiler-related criterion when traversing the movie graph in Algorithm 1. Specifically, we added a penalty when selecting shots that are in “spoiler-sensitive” graph neighborhoods. We identified such neighborhoods by measuring the shortest path from the last two TPs, which are by definition the biggest spoilers in a movie. However, this variant of our algorithm resulted in inferior performance and we thus did not pursue it further. We believe that such a criterion is not beneficial for proposing trailer sequences, since it discourages the model from selecting exciting shots from the latest parts of the movie. These high-tension shots are important for creating interesting trailers and are indeed included in real-life trailers. More than a third of professional trailers in our dataset contain shots from the last two TPs (“Major setback”, “Climax”). We discuss this further in the Appendix.
We also manually inspected the generated trailers and found that spoilers are not very common (i.e., we identified one major spoiler shot in a random sample of 12 trailers from the test set), possibly because the probability of selecting a major spoiler is generally low. And even if a spoilersensitive shot is included, when taken out of context it might not be enough to unveil the ending of a movie. However, we leave it to future work to investigate more elaborate spoiler identification techniques, which can easily be integrated to our algorithm as extra criteria.
This paper is available on arxiv under CC BY-SA 4.0 DEED license.
[7] Performance on the test set is lower because we only consider trailer labels from the official trailer, while the dev set contains multiple trailers.
[8] We do not include ground-truth trailers in the human evaluation, since they are post-processed (i.e., montage, voice-over, music) and thus not directly comparable to automatic ones.