

This article is the third in the series of future technology articles that I wrote:
- The Collective loves Data: How Big Data is Shaping, and predicting, our Future
- Warp Core of Confidence: How Blockchain Creates Trust in the Digital Frontier
I’m writing this series because even as cutting-edge technologies are shaping our world—as Marc Andreessen of Andreessen Horowitz says, “software is eating the world”—the complexities of their development are not well understood. I decided to write a trilogy that would simplify the understanding of these emerging technologies that are shaping our future.
I am Manoj Boopathi Raj, a Senior Software Engineer at Google. I’ve worked on Google products used by hundreds of millions of users, perhaps even you. If you’ve ever used Google AI Assistant in your car, I made sure it actually understands you past all the noise of the road and highway. I made sure that when you say ‘take a selfie’ your Android phone does exactly that. I’ve also kept spam out of YouTube, so your search results are exactly what you’re looking for and made sure your e-sim enabled Android phone is always connected to the strongest network, so you are never stuck with a loading screen. And yes, I believe humanity should ‘boldly go where no man has gone before’.
Today, the technology I’m most fascinated by are Large Language Models (LLMs) and how they’re revolutionizing human-computer interactions. You may ask, what are LLMs, and why do they matter? I cannot understate their importance to the next decade of nearly every industry. Companies that master it will be industry sector leaders; employees will be on a fast track for success. LLMs are at the core of every AI that is trained and will be trained in the future to perform every and any action.
What are Large Language Models (LLMs)
LLMs are data models trained on colossal amounts of text data, ingesting books, articles, code, and other forms of written content. This firehose of information allows them to grasp the nuances of language, including statistical relationships between words and how they're used in context. Once the data has been collected, artificial intelligence and machine learning applications empower LLMs to perform a variety of tasks, including:
- Generating human-quality text: LLMs can create realistic and coherent sentences, paragraphs, and even different creative text formats like poems or scripts.
- Understanding and responding to your questions: By analyzing the context of your query, LLMs can formulate informative answers that address your specific needs.
- Translating languages: LLMs can decipher the intricacies of different languages, enabling them to translate text with surprising accuracy.
- Writing different kinds of creative content: LLMs can be instructed to write in specific styles or tones, making them useful for crafting marketing copy, blog posts, or even musical pieces.
- Summarizing factual topics: LLMs can condense lengthy articles or research papers into concise summaries, highlighting key points and eliminating irrelevant details.
- Classifying and organizing information: LLMs can categorize text data based on predefined criteria, making them valuable for tasks like sentiment analysis or topic modeling.
Building the LLM is a two-step process:
- Pre-training: Building a Foundation with Massive Textual Data
-
Data Sources: LLMs are pre-trained on massive datasets of text and code, often in the order of terabytes or even petabytes, which can be compared to most people’s interactions with computers being orders of magnitude smaller, on the level of megabytes or gigabytes. This data can be curated from web scraping tools, public document archives, or proprietary datasets. Common formats include books (e.g., Project Gutenberg), articles (e.g., Wikipedia, news archives), code repositories (e.g., GitHub), and social media conversations (after anonymization and ethical considerations).
-
Tokenization: The text data is pre-processed by splitting it into individual units called tokens. Tokenization strategies can vary depending on the chosen approach for an LLM. Here are two common methods:
- Word-based tokenization: This is the simplest approach, where each word is considered a separate token. However, it can struggle with rare words or out-of-vocabulary (OOV) tokens.
- Subword tokenization: This approach splits words into smaller units called subwords, such as characters or morphemes (meaningful units). Techniques like Byte Pair Encoding (BPE) or WordPiece are commonly used for this purpose. Subword tokenization allows the model to handle OOV tokens by combining known subwords.
-
Word Embeddings: Each token is converted into a dense vector representation known as an embedding. This embedding is typically low-dimensional (e.g., 300 or 512 dimensions) but captures the semantic meaning of the word and its relationship to other words within the vocabulary. Popular embedding techniques include word2vec, GloVe, and contextualized embeddings like BERT or XLNet. These techniques leverage statistical properties of the surrounding text to create more nuanced and context-dependent embeddings.
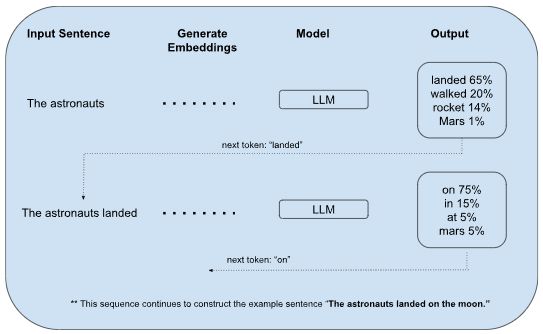
-
Transformer Decoder Network: At the heart of the pre-training process lies a deep learning architecture called a transformer decoder network. This network consists of multiple encoder-decoder layers stacked together. Here's a breakdown of the key components:
- Encoder Layers (Pre-trained separately): These layers, though not directly used during pre-training in a decoder-only architecture, are crucial for understanding word relationships. They typically employ a self-attention mechanism that allows the model to attend to relevant parts of the input sequence, capturing long-range dependencies between words (e.g., how a subject at the beginning of a sentence relates to a verb much later). Commonly used techniques include vanilla transformers or convolutional transformers.
- Decoder Layers: During pre-training, the decoder layers receive a sequence of word embeddings and attempt to predict the next word in the sequence using a masked language modeling (MLM) objective. This objective involves masking out a certain percentage of words in the input sequence and training the model to predict the masked words based on the context provided by the surrounding words. The prediction is based on the decoder's internal state, influenced by the encoder's pre-trained understanding of word relationships, and the attention mechanism that focuses on relevant parts of the input sequence.
- Loss Function and Optimization: The model's prediction is compared to the actual next word in the sequence using a loss function like cross-entropy loss. This loss is then used to backpropagate errors and update the weights and biases within the network through an optimization algorithm like Adam or RMSprop. This process iterates over the entire training dataset, allowing the LLM to learn the statistical patterns and relationships between words in the language.
2. Fine-Tuning: Specialization for Real-World Tasks (with Technical Details)
Pre-training equips the LLM with a strong foundation in language understanding. However, to excel at specific tasks, LLMs undergo further training on a smaller dataset curated for that particular domain. This dataset is labeled with examples relevant to the target goal. Here's a deeper dive into fine-tuning techniques with a technical focus:
-
Supervised Fine-Tuning:
- Freezing vs. Fine-tuning Layers: During supervised fine-tuning, a critical decision involves selecting which layers of the pre-trained model to update. Here are two common strategies:
- Freezing the Encoder: In this approach, the encoder layers pre-trained on the massive text corpus are frozen (weights remain unchanged). Only the decoder layers and potentially the final output layer are fine-tuned on the task-specific dataset. This is because the encoder layers have already captured generic language understanding, and retraining them might disrupt this valuable knowledge.
- Fine-tuning the Entire Model: This approach allows all layers of the pre-trained model to be adjusted during fine-tuning. While it offers more flexibility for the model to adapt to the specific task, it requires careful monitoring to prevent overfitting, especially when the fine-tuning dataset is smaller than the pre-training data.
- Loss Functions: Supervised fine-tuning often leverages task-specific loss functions to optimize the model's performance. Here are some common examples:
- Classification Tasks (e.g., sentiment analysis): In tasks where the model needs to classify text into predefined categories (positive/negative sentiment), the cross-entropy loss function is commonly used. This function measures the difference between the predicted probability distribution and the true one-hot encoded label.
- Regression Tasks (e.g., question answering): When the model predicts a continuous value (e.g., a score or a probability), loss functions like mean squared error (MSE) or mean absolute error (MAE) might be used. These functions measure the average squared or absolute difference between the predicted and actual values.
- Sequence-to-Sequence Tasks (e.g., machine translation): For tasks involving generating a new sequence of text based on an input sequence, the cross-entropy loss is again applicable. However, it's often calculated over the entire predicted sequence length to penalize errors throughout the generation process.
- Freezing vs. Fine-tuning Layers: During supervised fine-tuning, a critical decision involves selecting which layers of the pre-trained model to update. Here are two common strategies:
-
Unsupervised Fine-tuning:
- Loss Functions and Training Objectives: Unlike supervised learning, unsupervised fine-tuning doesn't have readily available labels for each data point. Here, techniques like autoencoders or contrastive learning objectives are employed:
- Autoencoders: In this approach, the LLM is forced to reconstruct the input data itself. The model receives a text sequence as input, encodes it into a latent representation, and then attempts to decode this representation back into the original sequence. The loss function is calculated based on the difference between the original and reconstructed sequences, encouraging the model to capture the essential structure and information within the data.
- Contrastive Learning Objectives: These objectives involve creating training examples where similar data points are pulled closer together in the model's latent space, while dissimilar ones are pushed further apart. This can be achieved through techniques like Noise Contrastive Estimation (NCE) or multi-sentence ranking tasks. By focusing on these relationships within the unlabeled data, the model learns relevant representations for the target domain.
- Loss Functions and Training Objectives: Unlike supervised learning, unsupervised fine-tuning doesn't have readily available labels for each data point. Here, techniques like autoencoders or contrastive learning objectives are employed:
-
Reinforcement Learning from Human Feedback (RLHF):
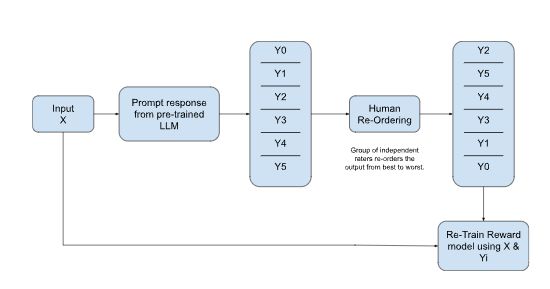
- Reward Functions: RLHF incorporates human feedback to guide the fine-tuning process. Here, humans evaluate different response options generated by the LLM for a given prompt. A reward function is then designed to assign higher rewards to responses judged as more relevant, informative, or creative. The model is fine-tuned by maximizing the expected cumulative reward over a sequence of interactions.
- Challenges: RLHF can be computationally expensive due to the need for human evaluation and reward assignment. Additionally, designing effective reward functions can be challenging, as human preferences can be subjective and nuanced.
Additional Considerations:
- Learning Rate Tuning: The learning rate is a crucial hyperparameter that controls the magnitude of updates to the model's weights during fine-tuning. A smaller learning rate helps prevent overfitting on the fine-tuning dataset, while a larger learning rate might lead to faster convergence but also increase the risk of overfitting. Techniques like learning rate scheduling can be employed to adjust the learning rate dynamically throughout the training process.
- Early Stopping: To prevent overfitting, a technique called early stopping can be used. Here, the model's performance is monitored on a separate validation set during fine-tuning. If the validation performance starts to decline after a certain number of epochs (training iterations), the training process is stopped to avoid memorizing the specific details of the input data.
- Regularization Techniques: In addition to early stopping, various regularization techniques can help reduce overfitting during fine-tuning. These techniques introduce constraints that prevent the model from becoming overly complex and dependent on the specific training data:
- L1/L2 Regularization: These methods penalize the model for having large weights. L1 regularization (LASSO regression) encourages sparsity by driving some weights to zero, while L2 regularization (Ridge regression) shrinks the weights towards zero but doesn't necessarily eliminate them entirely. This helps prevent the model from fitting too closely to random noise in the data.
- Dropout: This technique randomly drops out a certain percentage of neurons during training, forcing the model to learn robust representations that are not overly reliant on any single neuron or group of neurons.
- Transfer Learning Across Tasks: Once a model is fine-tuned for a specific task, the learned knowledge can be leveraged as a starting point for fine-tuning on related tasks. This is called transfer learning and can be particularly beneficial when dealing with limited data for the new task. By leveraging the pre-trained and fine-tuned model weights, the new task can potentially achieve better performance with less fine-tuning data compared to training from scratch.
Fine-tuning is a crucial step in transforming a general-purpose LLM into a powerful tool for real-world applications. By carefully selecting the fine-tuning approach, loss functions, hyperparameters, and regularization techniques, we can unlock the potential of LLMs to excel in various tasks, from generating different creative text formats to performing complex question answering or machine translation. As research in this field continues to evolve, we can expect even more sophisticated fine-tuning methods to emerge, further pushing the boundaries of LLM capabilities.
The development and fine-tuning of LLMs are pivotal in building the future, as these models can understand and generate human-like text, making digital assistants more responsive and intelligent. The potential of LLMs extends far beyond current applications, promising to revolutionize industries, streamline processes, and create more personalized user experiences. As we continue to explore the capabilities of LLMs, I am excited to be at the forefront of this technological evolution, shaping the future of AI-driven interactions, and I hope you are as excited as I am about how the next generation of LLMs will further change the world.