

In large monolithic applications, error tracking and monitoring can become ineffective due to unclear ownership. This guide proposes a structured approach to assign accountability using domain annotations to enhance monitoring efficiency and team responsibility.
Monitoring such applications, especially with multiple teams, poses challenges. Without clear ownership, error tracking tends to be generic and often ignored. While having on-call engineers determine which team should respond to monitoring alarms is one solution, a more efficient approach is to embed domain and team information directly into your monitoring system.
Existing Solutions for Enhancing Ownership of Large Applications
Microservices
Microservices architecture can effectively include domain and team information by breaking down a monolithic application into smaller, independent services. However, adopting them comes with significant drawbacks:
- Increased Complexity and Development Time: Each service needs to communicate with others, often requiring well-defined APIs, handling network latency, and managing distributed data consistency.
- Difficulty in Reverting Failed Transactions: A single business transaction might span multiple services, and handling failed transactions across these services can be challenging.
- Need for Establishing Clear Domains and Service Boundaries: Clear domain boundaries are needed to avoid excessive inter-service communication and to ensure that each service remains cohesive and manageable.
- Time-consuming transition: Splitting an existing monolith into microservices is often a lengthy and costly process. This transformation can take months or even years, during which product development may slow down or be blocked
Modular Monolith
Creating a modular monolith is another approach to managing clear ownership within a monolithic application. Unlike microservices, a modular monolith organizes the application into distinct, cohesive modules that can be developed and maintained independently by different teams. This approach has several advantages and challenges:
- Significant Refactoring Process: Although less drastic than transitioning to microservices, creating a modular monolith still requires refactoring the codebase to establish clear module boundaries and responsibilities
- No Clear Team Ownership Besides Codebase: Modular monoliths can enhance team ownership by assigning specific modules to different teams. However, this approach does not inherently provide clear team ownership within the code, nor does it add domain or team information to the monitoring system
Assigning Domains to Classes and Functions
Imagine marking classes and functions with domains, and mapping these domains to the respective teams within the codebase. This is where domain annotations come in.
Introduction to Domain Annotations
Domain annotations allow you to label every part of your application's code, clearly indicating accountability. By tagging parts of your code with domain annotations, you can:
- Avoid Refactoring: Apply domain annotations granularly without extensive refactoring.
- Simplify Log and Trace Management: Filter logs and traces based on criteria like team responsibility, enabling quick identification and resolution of issues.
- Maintain Accurate Tracking: Adapt to changes in team responsibilities seamlessly, as annotations are tied to domains rather than team names.
- Enhance Accountability: Clearly define team responsibilities for each domain, improving organization and targeted monitoring.
- Improve Monitoring Efficiency: Facilitate better monitoring practices by providing precise accountability, and enhancing overall efficiency.
Domain Annotations Processing
As an example, let’s explore how Domain Annotations are processed for REST requests.
Here’s a high-level overview of the process depicted in the following diagram:
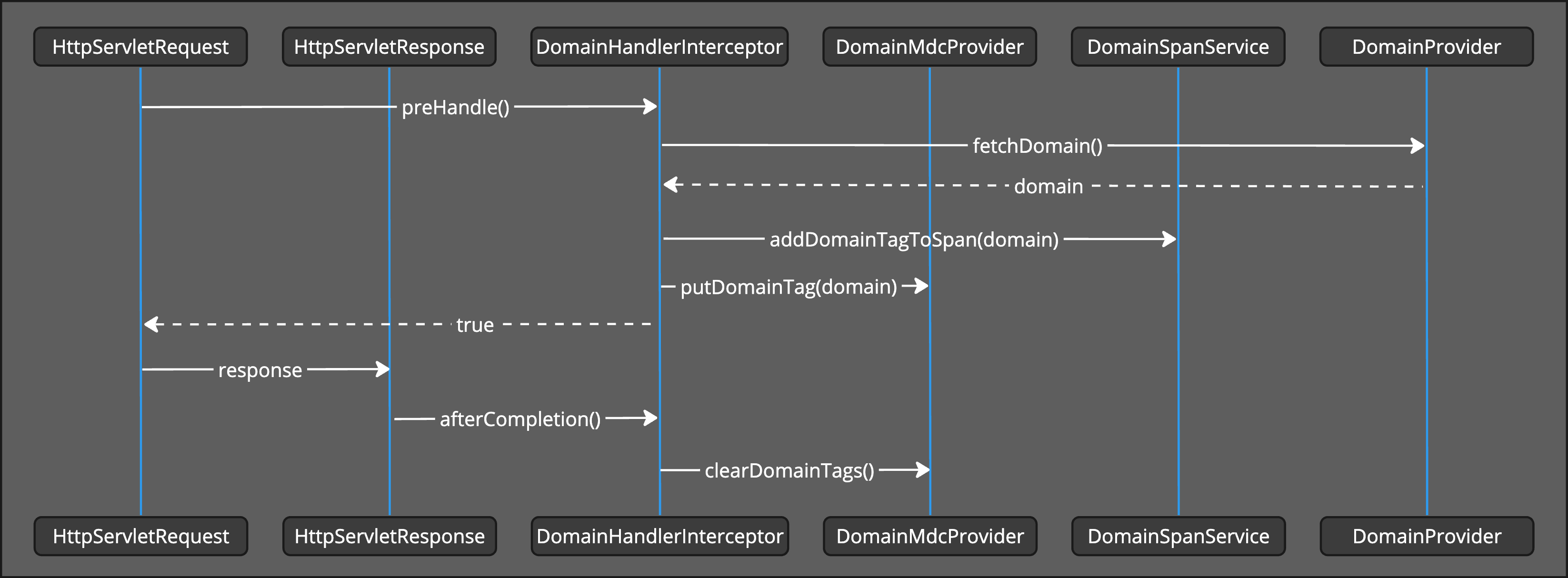
Key Components
- DomainProvider: Identifies the domain associated with specific handler methods or beans. It helps in finding domain annotations in AOP (Aspect-Oriented Programming) and MVC (Model-View-Controller) calls.
- DomainSpanService: Adds domain tags to spans, which are units of work in tracing systems. This service ensures that each span is tagged with the appropriate domain information.
- DomainMdcProvider: Manages domain tags within the MDC (Mapped Diagnostic Context), a feature of logging frameworks that allows tagging log entries with contextual information.
- DomainHandlerInterceptor: Intercepts web requests, ensuring that each request is tagged with the appropriate domain information for better monitoring and traceability.
For more information, refer to the monolith-domain-splitter library.
Sorting Out Who Owns What Code
Defining ownership at the class level is straightforward with domain annotations. By applying top-level annotations to main classes, ownership propagates down to all detailed resources within those classes. Each team can label classes they own with the appropriate domain annotations, ensuring clarity and accountability without marking every single method.
If multiple teams own code in one class and immediate refactoring isn’t appropriate, you can mark individual methods with different domain annotations. These method-level annotations take priority over class-level annotations, allowing specific methods to be assigned to different teams, and providing flexibility without complicating the overall structure.
Overcoming Not Supported By Annotations Cases
While domain annotations are handy, some cases may not support them. For instance, we encountered issues with Quartz job creation due to a clash between Quartz's AOP logic and the AOP logic used for domain annotations.
For jobs and processes that cannot be annotated directly, we used the DomainTagsService within the parent job implementations. This approach allowed us to add domain tags manually within the job's execution logic.
Here’s an example of how we integrated DomainTagsService into a Quartz job:
final override fun execute(context: JobExecutionContext) {
domainTagsService.invoke(domain) {
withLoggedExecutionDetails(context, ::doExecute)
}
}
Introduction of Artificial Services
To simplify monitoring each team's activities in Datadog, you can assign artificial service names for spans of different teams. This approach ensures every team has a dedicated section in Datadog's monitoring tools. While using artificial service names can be confusing if you have many services to manage, it becomes manageable with a limited number of backend services.
Adding prefixes to these artificial service names helps maintain organization and clarity in your Datadog setup, making distinguishing them from real services easier.
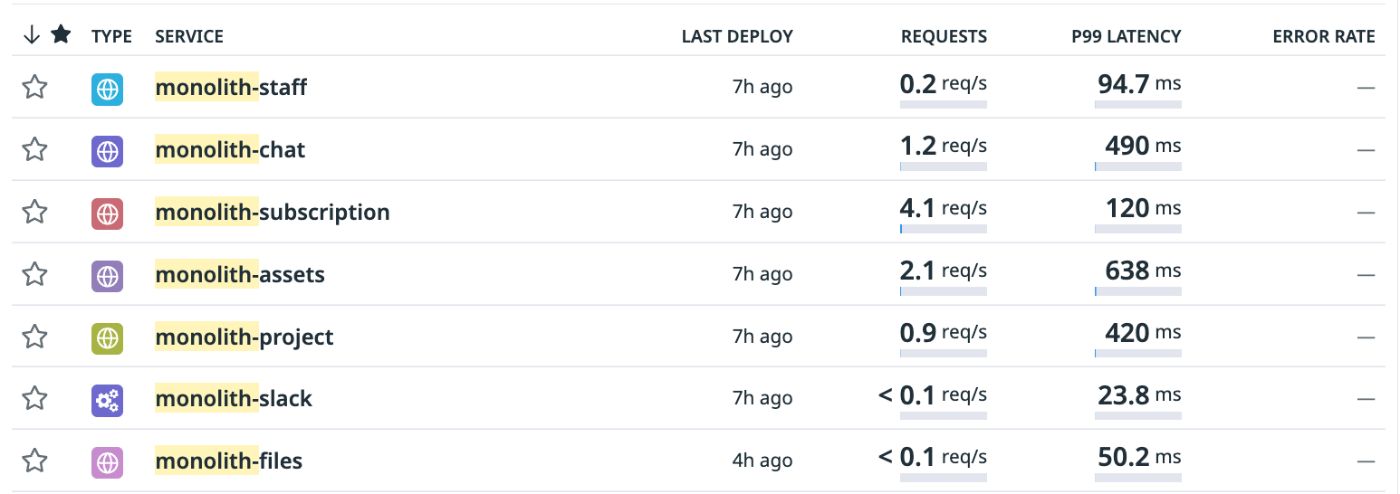
Why Not Use Artificial Services for Logs?
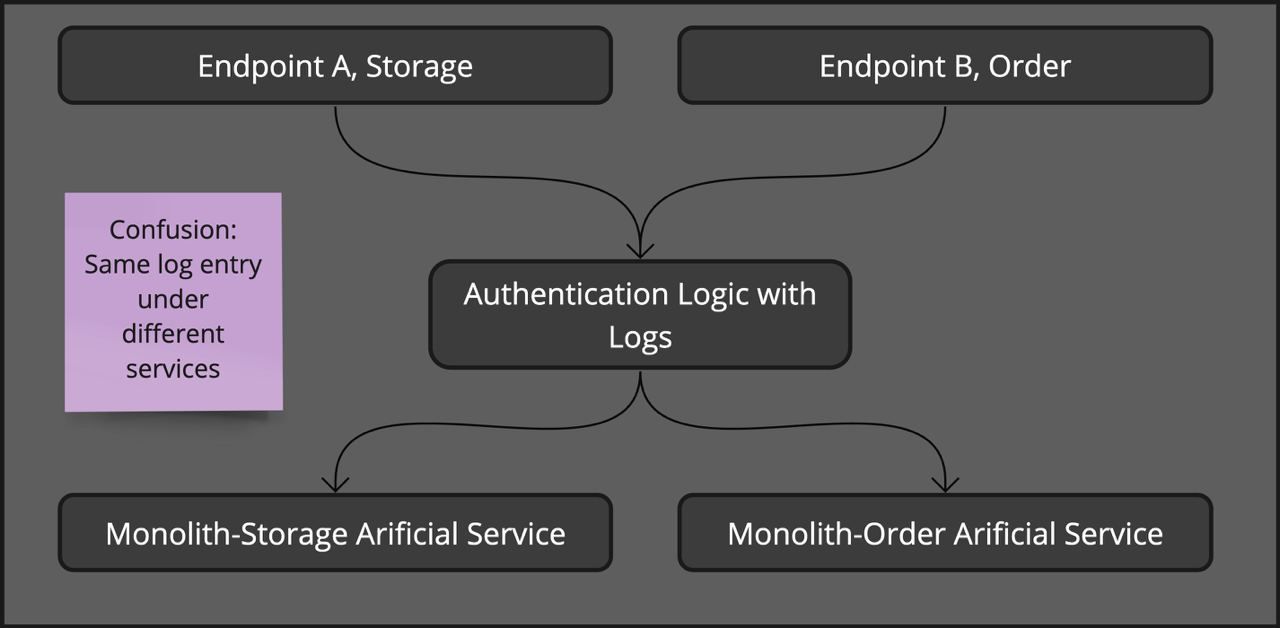
Using artificial service names for logs can create confusion, as the same log entry might appear under different services.
For example, consider two endpoints using the same authentication service. The authentication logic will produce logs under different artificial services if these endpoints are annotated with different domains. This could create confusion when exploring logs, as they appear under multiple service names.
To avoid this issue, it's better to apply artificial service names only to spans that are aggregated together in traces, reducing confusion.
Here is a visual representation of this problem:
Using Artificial Services in Monitoring and Dashboards
Using artificial services enables you to work with APM traces and filter by service in Datadog Metrics, which are stored for an extended period, allowing for tracking changes over a prolonged period.
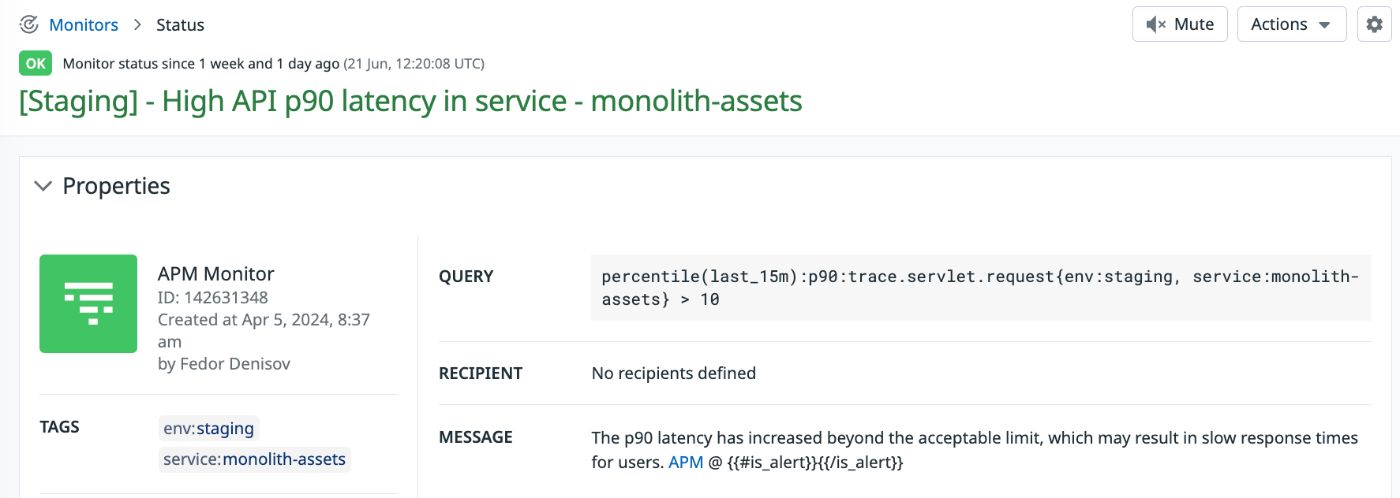
Example of Monitor
Below is a screenshot of a monitor in Datadog that uses the artificial service name monolith-assets in the query:
Example of Dashboard
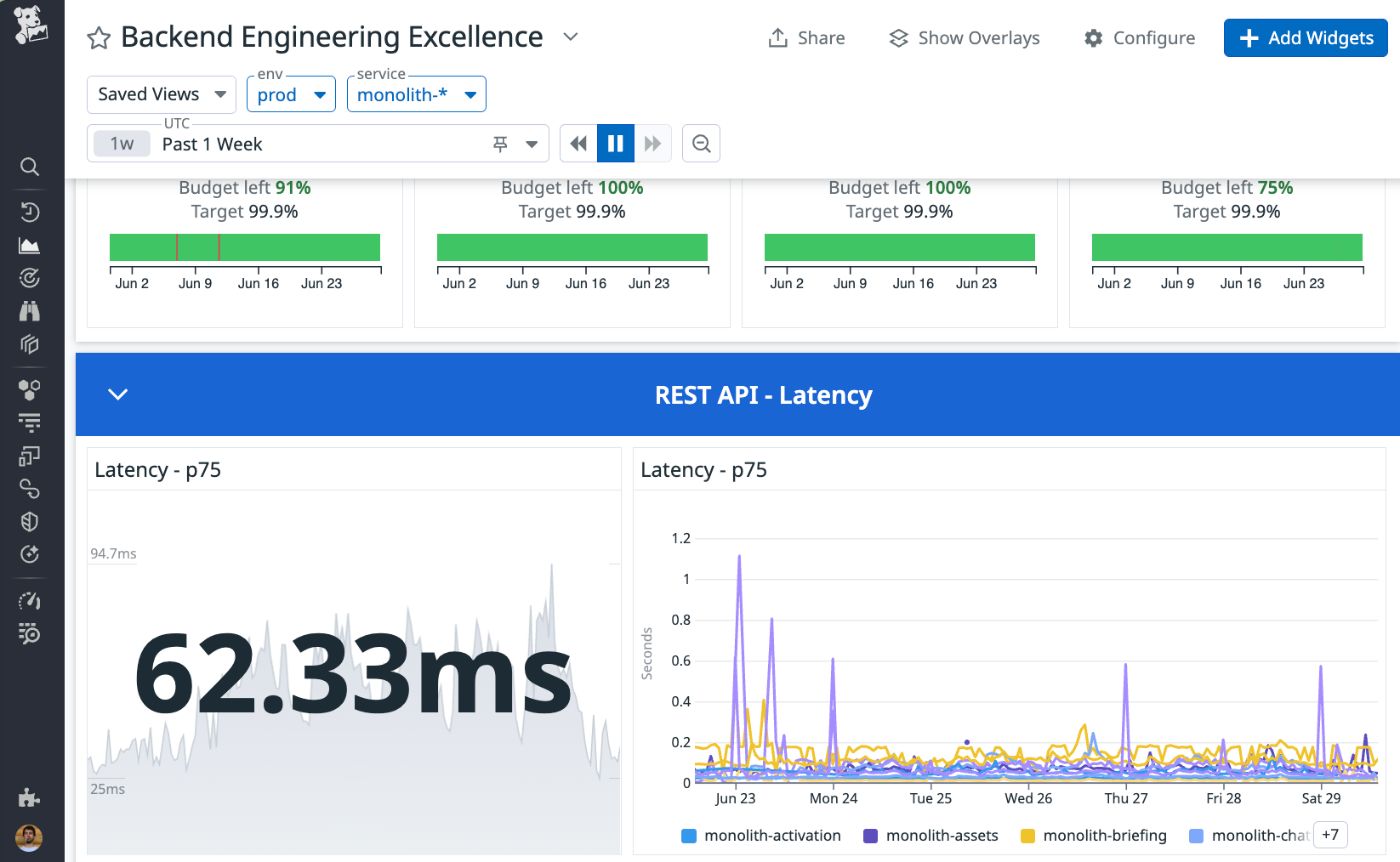
Below is a screenshot of a dashboard in Datadog that uses the artificial services prefix monolith-* in the filter. As you can see, there is also a separate latency on the chart for each service. All other service metrics are also available separately.
Step-by-Step Approach to Using Domain Annotations
This guide outlines the steps to integrating domain annotations into your project using the monolith-domain-splitter library, which requires the Datadog agent for full functionality. While adding domain and team annotations to logs may work without Datadog, it has not been thoroughly tested in such scenarios.
1. Define Domains and Teams
Use enums to represent different domains and teams within your application
enum class DomainValueImpl(
override val team: Team,
) : DomainValue {
PROJECT(TeamImpl.LIONS),
FILE(TeamImpl.SNAILS),
}
enum class TeamImpl : Team {
LIONS,
SNAILS,
}
2. Add Dependencies
Add monolith-domain-splitter library and Opentracing dependencies.
If you use Gradle, add to your build.gradle.kts file:
dependencies {
api("io.opentracing:opentracing-api:0.33.0")
api("io.opentracing:opentracing-util:0.33.0")
implementation("io.github.feddena.monolith.splitter:monolith-domain-splitter:0.0.2")
}
3. Annotate Your Application Class
Annotate your main application class to include the monolith-domain-splitter package for component scanning.
package your.app.pkg
@SpringBootApplication(scanBasePackages = ["your.app.pkg", "io.github.feddena.monolith.splitter"])
class StorageApplication
fun main(args: Array<String>) {
runApplication<StorageApplication>(*args)
}
4. Annotate Your Classes and Methods
Use the @Domain annotation to mark your classes and methods with specific domains.
@Domain("FILE")
class FileEndpoint {
// Your endpoint logic
}
5. Handle Unsupported Cases
For cases that cannot be annotated directly, use DomainTagsService to wrap the logic.
fun executeNotSupportedByAnnotationsLogic() {
domainTagsService.invoke(domain) { executeLogic() }
}
6. Register Your Custom Domains to the Registry
@Configuration
@EnableAspectJAutoProxy
class DomainConfiguration(
private val domainRegistry: DomainRegistry,
) {
init {
DomainValueImpl.entries
.forEach { domainRegistry.registerDomainValue(it) }
}
}
7. Add DomainTraceInterceptorConfiguration to Configure Artificial Services Usage
@Configuration
class DomainTraceInterceptorConfigurationImpl : DomainTraceInterceptorConfiguration {
// name of the service in datadog if you wish to override it
override fun getServicesToOverride(): Set<String> {
return setOf("real-service-to-override")
}
// prefix that will be used to create artificial services names
// artificialServiceName = getServiceNamePrefix() + team
override fun getServiceNamePrefix(): String {
return "monolith-"
}
}
8. Add WebMvc Interceptor to Support Annotations on REST Requests
@Component
class WebMvcConfigurerDomain(
private val domainHandlerInterceptor: DomainHandlerInterceptor,
) : WebMvcConfigurer {
override fun addInterceptors(registry: InterceptorRegistry) {
registry.addInterceptor(domainHandlerInterceptor)
}
}
9. Monitor with Datadog
Use artificial service filters for monitors, dashboards, and APM traces filtering in Datadog to keep track of different domains and teams. Ensure your project has the Datadog agent configured for full functionality.
Wrapping Up
Domain annotations provide a straightforward approach to simplifying the monitoring of monolithic applications in Datadog. Use the monolith-domain-splitter library in your project to ensure that each domain in your monolithic application is well-organized and tracked for better observability and accountability.
Key Takeaways
-
Enhanced Ownership and Accountability: By annotating parts of your code with domain annotations, you can clearly define which team is responsible for each domain. This facilitates better organization and targeted monitoring.
-
Improved Log and Trace Management: Domain annotations allow you to filter both logs and traces based on specific criteria, such as team responsibility, enabling quick identification and resolution of issues.
-
Flexibility with Artificial Services: Using artificial service names for spans (not logs) ensures that logs remain clear and traceable to their true origins, avoiding confusion.
-
Overcoming Integration Challenges: For cases where annotations cannot be directly applied, such as with certain job execution frameworks like Quartz, using services like
DomainTagsServicedirectly in the job implementations ensures that domain-specific monitoring can still be maintained.