Authors:
(1) Rui Duan University of South Florida Tampa, USA (email: ruiduan@usf.edu);
(2) Zhe Qu Central South University Changsha, China (email: zhe_qu@csu.edu.cn);
(3) Leah Ding American University Washington, DC, USA (email: ding@american.edu);
(4) Yao Liu University of South Florida Tampa, USA (email: yliu@cse.usf.edu);
(5) Yao Liu University of South Florida Tampa, USA (email: yliu@cse.usf.edu).
Table of Links
Parrot Training: Feasibility and Evaluation
PT-AE Generation: A Joint Transferability and Perception Perspective
Optimized Black-Box PT-AE Attacks
V. OPTIMIZED BLACK-BOX PT-AE ATTACKS
In this section, we propose an optimized PT-AE generation mechanism to attack a black-box target model. We first investigate the TPRs of PT-AEs generated from combined carriers, then formulate a two-stage attack to generate PT-AEs against the target model.
A. Combining Carriers for Optimized PT-AEs
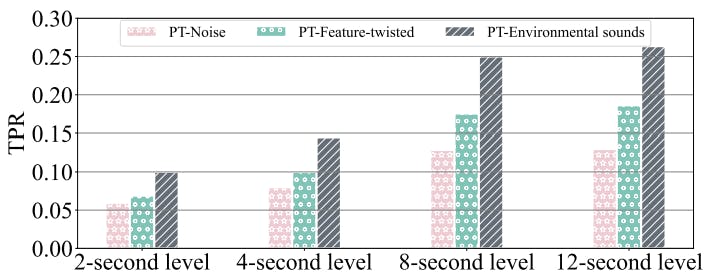
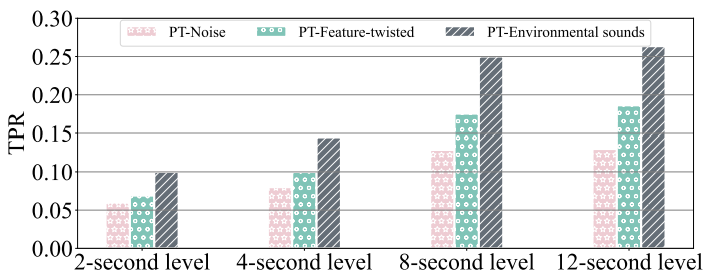
The findings in Fig 6 reveal that the environmental sound carrier achieves the highest TPR and should be a good choice to generate PT-AEs. But using the environmental sound carrier does not exclude us to further twist the auditory feature of the carrier or adding additional noise to it (e.g., an enrollment-phase attack [39] used both environmental sounds and noise). In other words, there is a potential way to combine the environmental sound carrier with feature-twisting or noise-adding method to further improve the TPR.
We consider two additional types of carriers: (i) Feature-twisted environmental sounds, and manipulating the pitch [113] or the rhythm [44] is a straightforward way to twist the features of environmental sounds. We follow the same feature-twisting procedure in Section IV-C2 to twist the pitch
and rhythm features of environmental sounds to generate PTAEs. (ii) Noise-based environmental sounds. We first add environmental sounds to the original speech and then use the noise attack procedure in Section IV-C2 to generate PT-AEs.
Fig. 7 shows the TPRs of various PT-AEs generated based on (i) adding noise to, (ii) twisting the rhythm, and (iii) twisting the pitch of a type of environmental sounds. We can find that the TPR is sensitive to the choice of environmental sounds. For example, the music sounds do not seem very effective to increase the TPRs even with twisted features. It is noted that natural sounds have overall higher TPRs than other types of carriers. For example, using the brook sounds can achieve 0.29 TPR compared with alarm (0.25), rooster (0.26), and Rock2 (0.16) in the existing dataset [47]. Moreover, Fig. 7 illustrates the uniform advantage of twisting the pitch of environmental sound over twisting the rhythm and adding noise. For example, built upon the hail sounds, twisting the pitch feature obtains a TPR of 0.26, substantially higher than twisting the rhythm (0.18) and adding noise (0.05). In addition, Fig. 7 shows that adding noise is the least effective way to improve the TPR. Based on the results in Fig. 7, we consider generating PT-AEs against a black-box target model via twisting the pitch feature of environmental sounds.
B. Two-stage Black-box Attack Formulation
We now formulate the black-box PT-AE attack strategy against a target speaker in a target speaker recognition model. The attack strategy consists of two stages.
In the first stage, the attacker needs to determine a set of candidate environmental sounds as there are a wide range of environmental sounds available and not all of them can be effective against the target speaker (as shown in Figure. 7). To this end, we first build a PT-surrogate model for the attacker, evaluate the TPR of each type of environmental sounds based on the surrogate model, and choose K sounds with the best
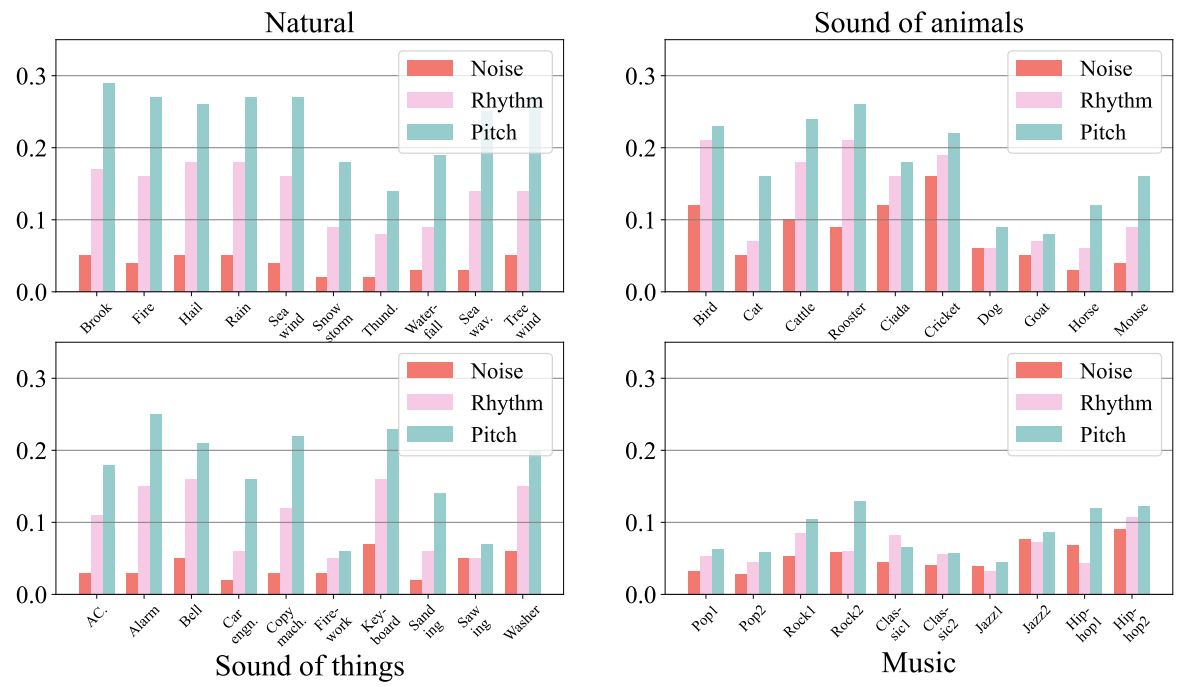
TPRs to form the candidate set. Then, we pre-process each environmental sound in the candidate set by shifting its pitch to obtain its best TPR, and obtain a new candidate set of K pitch-shifted sounds, denoted by {δk}k∈[1,K].

This paper is available on arxiv under CC0 1.0 DEED license.