This brings us to the end of this trilogy series focusing on performance evaluation metrics for conversation assistants.
- Part 1 - Metrics: Swallow the Red Pill
- Part 2 - Metrics Reloaded: The Oracle
- Part 3 - The Metrics Revolution: Scaling
What we have discussed so far?
I would highly encourage reading the first 2 articles of this series to get a more detailed understanding.
- User Perceived Metrics and User Reported Metrics form the foundation for a highly reliable conversational assistant.
- Reliability and Latency are two different aspects to evaluate end user performance for conversational agents.
- Never fully trust a metric - always question negative and positive movement in a metric.
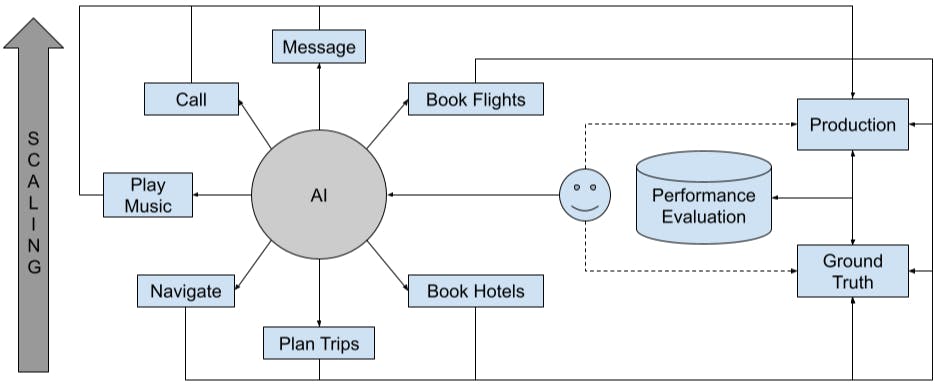
- There are 2 metric collection pipelines
- Ground truth metric measure performance end user metrics in a manual and semi-automated setting. This has high confidence but lower coverage.
- Production metric measure performance end user metrics from real users in production. This has low confidence but higher coverage.
- Metric collection from production should not affect degrading performance.
- Logs should be harmless and simple.
- Metrics derivation and logs should be orthogonal.
Scaling to multiple surfaces
This article will be focussing on how do we scale the metric instrumentation framework to accommodate new user cases across different form factors - phone, tablet, headsets, car etc.
Support different product features
It is important to note that different form factors may have different product features. However, for conversational assistants, the high level mental model should still be the same.
- How long does it take for assistant to start up?
- How long does it take for the AI agent to respond?
- How long does it take for the AI agent to complete a task end to end?
As a result, there is a need to enable metric collection from different log types along with customizations needed for additional form factor specific features.
Seamless Extension
The metric collection framework should work out of the box for new form factors without needing any specific change on metric collection framework.
This is essential to ensure that the metrics required for determining success for the conversational AI agent are available from early stage and can be used to plan the future roadmap for next milestones. This also removes additional engineering bandwidth and ensures that the metrics are measured in an objective manner.
The solution
I will be discussing a simple solution that can work for most use cases - transform the device specific logs to an uniform representation.
I am also the first author patent holder in this area - Standardizing analysis metrics across multiple devices. I will not be discussing low level details of the solution but the high level details.
Implementations relate to generating standardized metrics from device specific metrics that are generated during an interaction between a user and an automated assistant.
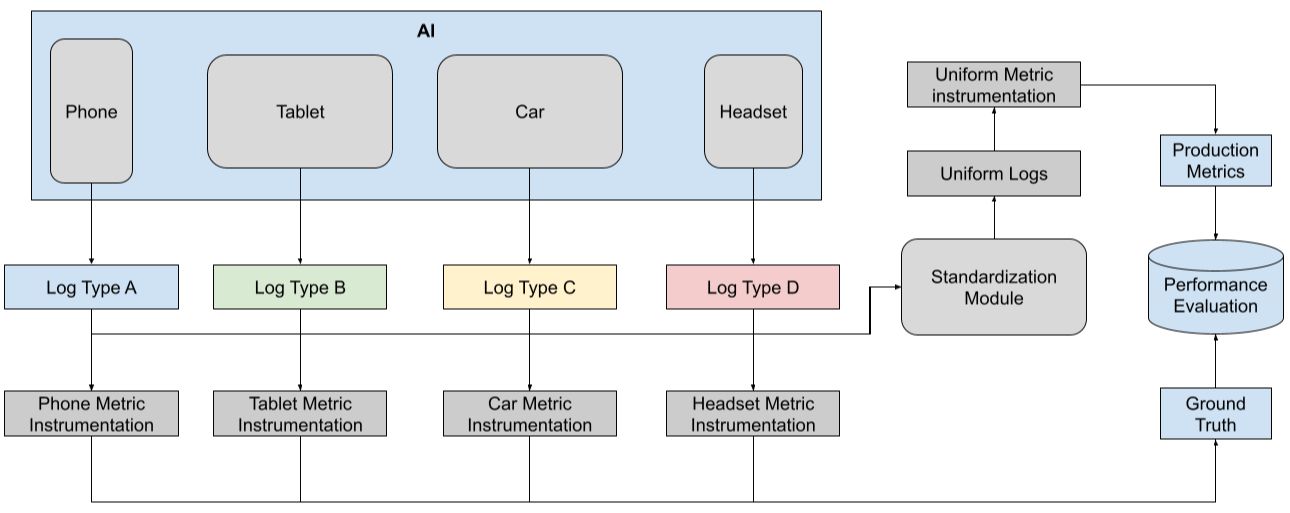
The solution consists of the following steps:
- Identify the metrics that are agnostic of the form factor - these are core metrics for the conversational AI agent in question.
- Identify the logging signals needed for instrumenting these metrics.
- Adding mapping configuration for the corresponding logging signals on each form factor.
- Transform the form factor specific logging signals to an uniform space which is agnostic of the form factor.
- The metric instrumentation framework will only be based on the uniform logging signals.
Key Benefits
- Metric instrumentation framework and form factor based logging signals are decoupled from each other.
- It makes it easy to backfill or correct issues with metrics easily without needing changes on the specific form factor.
- Provides fast scaling to newer surfaces or upgraded tech stacks without affect the core metrics for the conversational agent.
Word of caution
It is important to note that “ground truth” metrics should continue to be based on device specific logs. This can help uncover issues with the metric instrumentation framework.
“Ground truth” metrics should always reflect the metrics with high confidence. It is crucial to remember to never fully trust metrics - “swallow the red pill”.
Conclusion
As AI applications integrate more into our daily lives, it is crucial to ensure that these AI agents are reliable for the end user. AI agents should be useful and usable. As a result, end user performance evaluation infrastructure provides a foundational backbone for the development of conversational agents. I hope this trilogy series provides a good starting point to understand and instrument these metrics at high level.