
Authors:
(1) Jianzhu Yao, The CoAI group, Tsinghua University, Beijing, China Department of Computer Science and Technology, Tsinghua University, Beijing, China Beijing National Research Center for Information Science and Technology;
(2) Ziqi Liu, The CoAI group, Tsinghua University, Beijing, China Department of Computer Science and Technology, Tsinghua University, Beijing, China Beijing National Research Center for Information Science and Technology;
(3) Jian Guan, The CoAI group, Tsinghua University, Beijing, China Department of Computer Science and Technology, Tsinghua University, Beijing, China Beijing National Research Center for Information Science and Technology;
(4) Minlie Huang, The CoAI group, Tsinghua University, Beijing, China Department of Computer Science and Technology, Tsinghua University, Beijing, China Beijing National Research Center for Information Science and Technology.
Table of Links
3 DIALSTORY Dataset
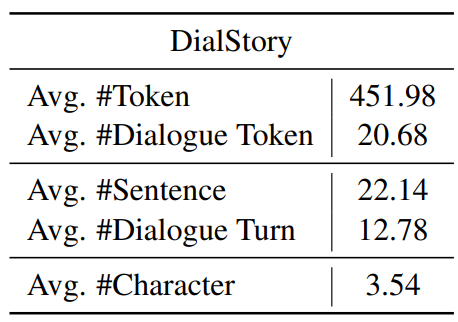
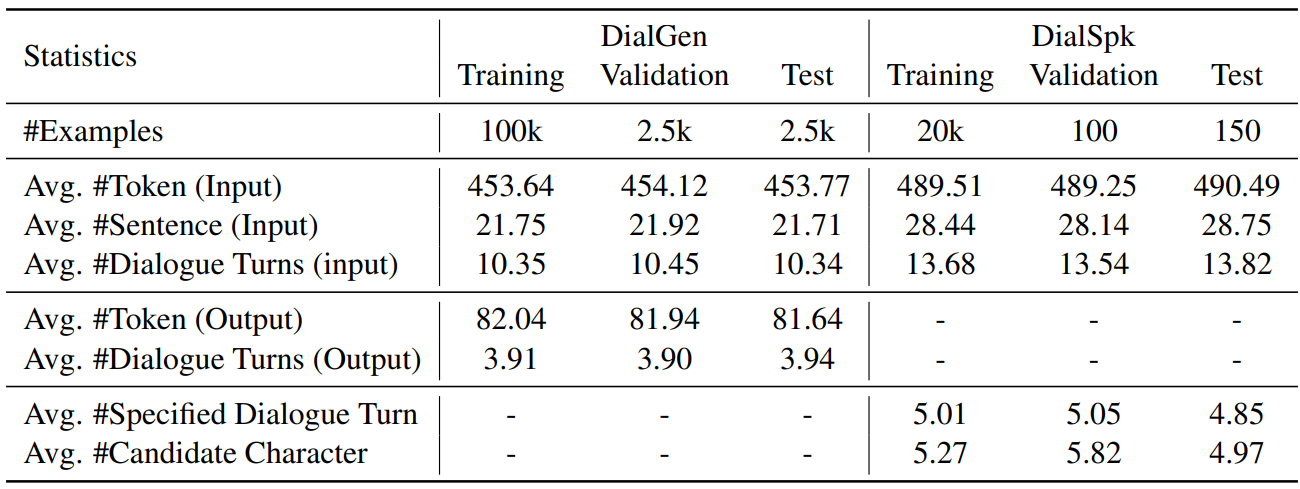
We construct the DIALSTORY dataset by randomly sampling 105k chapters from the Chinese novels released by Guan et al. (2022) with each chapter including at least ten dialogue turns. We also set a restriction that the number of tokens in all dialogue turns should account for at least 30% and at most 50% of the total length of the story, in order to keep a balance between the context and dialogue. We automatically annotate dialogue turns in these stories as text spans that are surrounded by quotation marks. Then, we use a pretrained named entity recognition model (Zhao et al., 2019) to identify all people’s names. Each distinct name corresponds to a character. We also conduct a manual annotation on 150 stories, and the accuracy of character identification is 718/746=96.2%, which shows the high quality of this automatic method. We then decide the speaker of the dialogue by recognizing the subjects of sentences before and after the dialogue turn using spaCy[1]. Table 1 shows the statistics of our dataset.
This paper is available on arxiv under CC 4.0 DEED license.
[1] https://spacy.io/