

Authors:
(1) P Aditya Sreekar, Amazon and these authors contributed equally to this work {sreekarp@amazon.com};
(2) Sahil Verm, Amazon and these authors contributed equally to this work {vrsahil@amazon.com;}
(3) Varun Madhavan, Indian Institute of Technology, Kharagpur. Work done during internship at Amazon {varunmadhavan@iitkgp.ac.in};
(4) Abhishek Persad, Amazon {persadap@amazon.com}.
Table of Links
- Abstract and Introduction
- Related Works
- Methodology
- Experiment
- Conclusion and Future Work
- References
3. Methodology
3.1. Problem Statement

3.2. Background
The Transformer architecture (Vaswani et al., 2017) is constructed by stacking multiple encoder blocks, where each block takes a sequence of embeddings as input and outputs a sequence of context aware embeddings. The encoder block consists of a multi-head self-attention (MHSA) layer followed by a position-wise feed-forward layer, with residual connections and layer norm before each layer. The MHSA layer comprises multiple self-attention units called heads, which learn interactions between input embeddings.


The output sequence is then recursively passed through subsequent encoder layers, allowing each successive layer to learn higher order feature interactions. The transformer’s depth controls the complexity of the learned representation, as deeper layers capture more complex interactions between features. Further, multiple self-attention heads are used in MHSA, enabling each head to attend to different feature sub-spaces and learning interactions between them, cumulatively learning multiple independent sets of feature interactions.
3.3. Rate Card Transformer
The rate card of a package consists of multiple features types, namely dimensional, route, service, item, and charge (Fig. 1a), where each feature type comprises multiple numerical and categorical features. The dimensional, route and service features are referred to as fixed length feature types, because each of them have a fixed number of features. Fixed length feature types are embedded to a sequence of tokens using a mixed embedding layer (MEL). For example, dimensional features d ∈ S[md, nd] are embedded to a d-dimensional token sequence of length md + nd. The MEL contains multiple embedding blocks, one for each feature in the feature type being embedded. Embedding lookup tables are used for embedding categorical features, while numerical features are embedded using continuous embedding blocks, as introduced in (Gorishniy et al., 2021).

The sequence of feature tokens is passed as input to a stack of L Transformer encoder layers that are able to learn complex, higher order interactions between the features. Finally, the pooled Transformer output is fed to a feedforward layer to predict the shipping cost Cˆ as shown in Fig. 1b.
We call the complete architecture the Rate Card Transformer (RCT). Trained to minimize the L1 loss between the predicted and actual shipping cost (Equation 3), RCT learns an effective representation of the dynamic rate card that allows it to accurately predict the shipping cost.
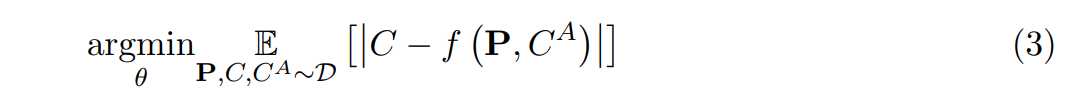
This paper is available on arxiv under CC BY-NC-ND 4.0 DEED license.